一、从人工智能到 Generative AI:技术演进简史
近年来,Generative AI(生成式人工智能)席卷全球。从 ChatGPT 聊天、Midjourney 画图、Copilot 辅助编程,再到 Runway 自动剪辑视频,它正不断刷新我们对「创造力」的想象。
对软件工程师来说,这场技术浪潮不仅关乎工具升级,更关乎工作方式的根本改变。但 Generative AI 究竟从哪里来?又为何如此强大?要理解它,我们需要回顾人工智能的发展脉络。
1.1 从规则系统到机器学习
最早的 AI 系统是专家系统:通过大量 if…then… 的规则模拟人类决策过程。你可以把它理解为一大堆硬编码逻辑——维护成本高,扩展性差。
后来,机器学习(Machine Learning) 兴起。与其手动写规则,不如喂给算法大量数据,让它「自己找规律」。
例如:
给定一堆带标签的猫狗图片,模型自动学会区分它们;
给定用户浏览记录,模型自动预测广告点击率。
这一阶段的 AI 可以做 「识别」 与 「分类」,但仍不具备 「理解」 与 「生成」 能力。
1.2 深度学习:数据驱动的感知能力
到了 2010 年前后,随着计算力提升和数据爆炸,深度学习(Deep Learning,也叫做神经网络(neural networks)) 崛起。它通过 「神经网络」 模拟人脑结构,自动提取更复杂的特征。
举个例子:
在图像识别中,传统方法需要手动定义“边缘”“角点”等特征;
而深度学习模型可以自动从原始像素中学出「这是一只狗」。
但图像和语言不同,语言是序列信息,还带有上下文语义。这正是 NLP(自然语言处理) 进入舞台的地方。
1.3 自然语言处理(NLP):让机器听懂人话
让计算机理解语言并不容易。中文中苹果可以是水果,也可以是苹果手机。这种语义歧义、上下文关联,远比图像识别复杂。
为了解决这些问题,NLP 技术引入了三大关键手段:
1. Tokenization(分词)
Tokenization(分词)让文本得以被数字化标注,从而使计算机能够运用统计方法(而非基于规则的模式)从数据中自动发现规律模式。
步骤:
- 从需要分词的文本开始处理。
- 根据特定规则(如遇到空格时)将文本拆分为单词。
- 去除停用词——剔除”the”、”a”等含义较少的干扰词,通常通过预置词典实现结构化过滤。
- 为每个唯一词符分配对应的数字编码。
类比理解:就像你解析一个 JSON 字符串,把原始输入转成结构化数组,方便后续处理。
2. Word Embedding(向量化)
从离散符号到连续向量
在自然语言处理中,词语最初只是离散的符号(tokens),计算机无法理解它们之间的语义关系。Word Embedding 技术通过将每个词语表示为多维空间中的连续向量(vector),成功解决了这个问题。
向量的语义
- 这些向量不是随机的:
- 每个维度都编码了特定的语义特征
- 向量的方向代表了词语的语义
- 语义相近的词语,其向量方向也越接近
如何衡量语义相似度?
- 我们使用余弦相似度来量化这种关系:
- 数值范围在-1 到 1 之间
- 越接近 1 表示语义越相似
- 完全无关的词语相似度接近 0
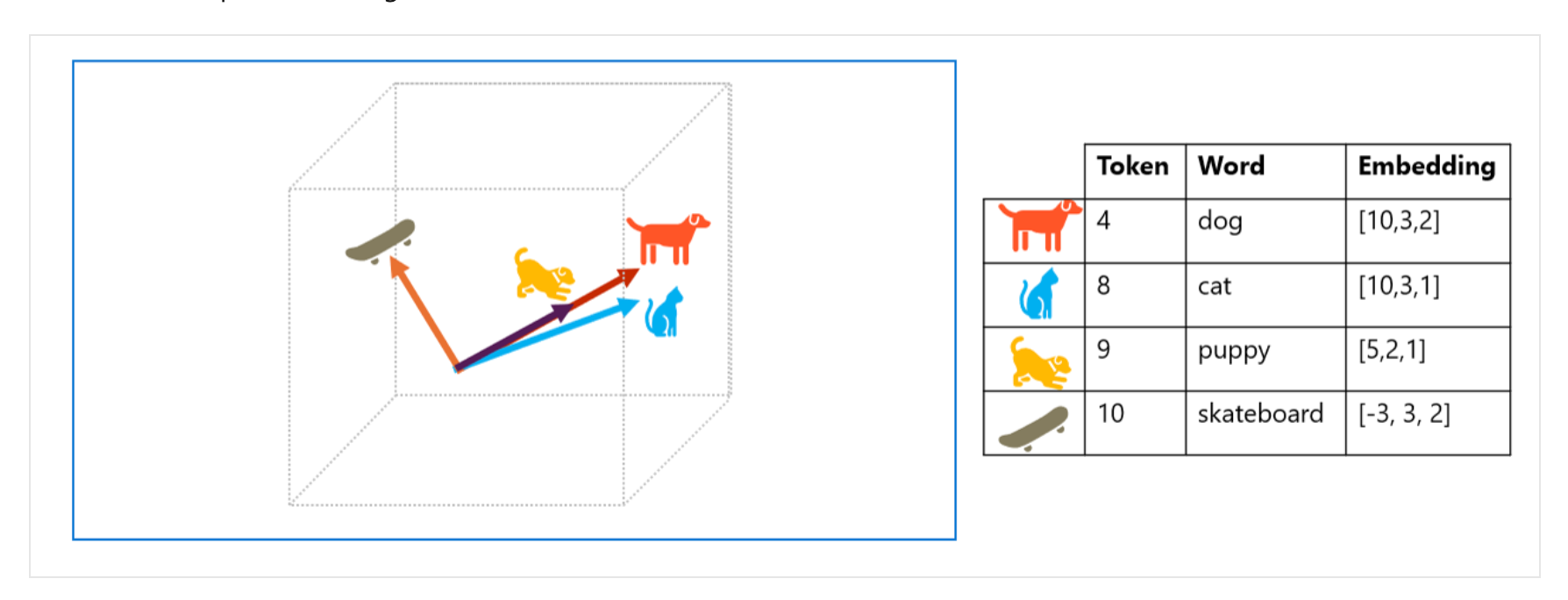
如图:
- “狗”和”小狗(puppy)”:最为接近
- “狗”和”猫”:比较接近,同属宠物
- “狗”和”滑板”:几乎没有关系
类比理解:相似的词距离更近,就像你在地图上按语义给词定位。
3. 上下文建模(建模语言结构)
语言的意义通常依赖上下文。比如“我吃苹果”中,“苹果”指水果,而“我喜欢苹果手机”中则是“苹果品牌”。
为此,我们需要一种方法,让模型在处理当前词时能考虑前后文。这就引出了模型结构的演进。
1.4 模型结构的演进:从 RNN 到 Transformer
在构建语言理解能力时,模型结构从简单到复杂经历了多个阶段:
RNN(Recurrent Neural Network):一次读一个词,逐步记住上下文信息,适合处理序列。
LSTM / GRU:为了解决 RNN “记忆力差”问题,改进了信息保留机制。
Transformer(现在的主力):Transformer 模型突破了 RNN 处理长文本序列的限制,其核心的 「注意力机制」 能自动为输入分配不同权重,使模型可以不受文本顺序约束而 「聚焦关键信息」。这种架构让 AI 能更有效地理解长距离语义关联,奠定了现代大语言模型的基础。Transformer 的成功标志着自然语言处理进入全新时代。
类比理解:RNN 就像你一句话一句话翻阅书籍, Transformer 就像你一下子读完全书,快速抓住重点。
1.5 Generative AI 登场:从理解到创造
有了这些技术铺垫,Generative AI 终于在近几年爆发。它不仅能理解语言、编码,还能 「续写」、「改写」、「重构」,具备类人类的生成能力。
这背后依靠的是:
超大规模 Transformer 模型(例如 GPT、Claude、Gemini 等)
高质量训练数据集(来自全网的文本、代码、图像)
强大的推理能力(每个词都是一步步预测出来的)
二、Generative AI 的工作机制揭秘
在上一章中,我们了解了语言建模的技术演进,并认识了 Transformer 这种强大架构。但真正使用生成式 AI,比如给 ChatGPT 提一个问题,AI 是如何推理、理解、生成回答的呢?
本章,我们就拆解 Generative AI 的工作机制。
1. 从输入到输出:一次完整推理流程
当你给一个生成式 AI 一个输入(Prompt)时,系统大致经历如下流程:
- Tokenization:把文本输入分成 tokens,并映射成向量。
- Embedding Lookup:将 tokens 转换为向量表示。
- Transformer Encoder/Decoder:通过一系列 Self-Attention、FeedForward 计算,更新每个 token 的隐藏状态。
- 预测下一个 token 的分布:模型输出一个概率分布,表示在当前上下文下,可能出现每个词的概率。
- 采样(Sampling)策略:根据概率分布,选择一个具体的下一个 token。
- 循环生成:把已生成的 token 加回输入,继续预测下一个,直到生成完成(比如达到最大长度、遇到结束符)。
类比理解:就像你调用一个链式函数,每步都基于前一步的输出继续处理,直到得到最终结果。
2. 生成不是一次性预测,而是一步步推理
非常重要的一点:
Generative AI 每次只预测「下一个最可能出现的 token」。
而不是一次性把整段话预测出来。
举例说明: 今天的天气
第一次推理,模型预测:
| 可能的下一个词 | 概率 |
|---|---|
| 很 | 30% |
| 不 | 20% |
| 下雨 | 10% |
| 晴朗 | 5% |
如果采样到了很,那么第一次推理变成:今天的天气 很
再次预测下一个词,比如:
| 可能的下一个词 | 概率 |
|---|---|
| 好 | 40% |
| 热 | 25% |
| 湿 | 15% |
如果采样到了好,那么第二次推理变成:今天的天气 很好
以此类推,一步步生成完整的句子。
3 Sampling 策略:不是总拿最大,而是讲究平衡
在每次预测下一个 token 时,选择哪个 token 其实有不同策略:
1. Greedy Search(贪心搜索)
- 每次都选概率最大的词。
- 生成确定、直接,但容易“卡壳”,句子单一。
类比理解:就像你总是选最短路径,但可能错过风景。
2. Top-k Sampling
- 只在概率最高的前 k 个词里随机抽选。
- 可以引入多样性,避免千篇一律。
例如设置 k=5,每次只在 top 5 的词中随机选择。
3. Top-p Sampling(又叫 nucleus sampling)
动态选择:只在累计概率超过 p 的词集合中抽选。
更加灵活,兼顾连贯性与创造性。
例如 p=0.9,意味着只考虑累计到 90%概率的那批可能性高的词。
4. Temperature(温度系数)
- 控制分布的平滑程度。
- 温度高(>1.0),分布更均匀 → 更随机。
- 温度低(<1.0),分布更陡峭 → 更确定。
1 | temperature = 0.7 # 比较平衡的设定 |
类比理解:Sampling 策略直接决定了 AI 生成的风格:保守还是富有创意。
4. 为什么每次生成的结果可能不同?
即使输入相同,生成的回答有时也会不同,这是因为:
使用了带随机性的 sampling 策略(比如 top-k, top-p)
设置了温度(temperature > 0)
类比理解:就像你面对同一个问题,可能因为当天心情、环境不同,回答也有细微变化。
如果想要完全确定性的输出,需要设置:
1 | top_p = 0 |
这时每次都只选最高概率的词,不带任何随机性。
5. Prompt 是怎样影响推理方向的?
Prompt(提示词)就像是引导模型推理的一组线索。
一个好的 prompt,能清晰地限定主题、风格、角色;
一个模糊的 prompt,会导致模型在多种可能路径中摇摆。
举例:
输入 prompt:
1 | 请写一段优雅的中文诗歌,主题是春天。 |
比直接输入
1 | 写一段文字。 |
能更精确地引导模型集中于「诗歌」「中文」「春天」这三个方向。
类比理解:prompt 就像函数调用中的参数(parameters),决定了函数执行的路径和结果
6. 小结:Generative AI 就像一步步玩的猜词游戏
总结一下,本章讲了:
- 生成式 AI 不是一次性生成整段文字,而是一步步预测下一个词;
- 每次预测用到概率分布,需要采样策略来平衡确定性与创造性;
- Prompt 就是引导生成方向的重要参数;
- 整个推理过程虽然简单,但依靠强大的 Transformer 网络支撑,才能实现流畅自然的输出。
理解了这些,我们就能更好地设计 Prompt、调控模型输出,为各种实际应用(比如聊天机器人、智能写作、代码生成等)打下基础。
三、Generative AI 的典型应用场景
随着模型能力不断提升,Generative AI 已经广泛应用于各个领域,不只是聊天对话那么简单。
在这一章,系统梳理生成式 AI 的主要应用方向。
4.1 文本生成(Text Generation)
文本生成是 Generative AI 最早、最广泛的应用之一。
4.1.1 聊天对话(Chatbot)
- ChatGPT
- DeepSeek
- 文心一言
本质:根据上下文动态生成自然语言回应。
4.1.2 内容创作(Content Creation)
- 写作辅助(文章、新闻、剧本起草)
- 社交媒体文案生成
- 营销邮件、广告语撰写
4.1.3 总结归纳(Summarization)
- 自动摘要长文档、报告
- 会议记录提取要点
本质:将冗长内容压缩为简洁、连贯的短文本。
4.2 代码生成与辅助(Code Generation)
随着 Copilot,Cursor 等工具的出现,代码生成成为软件工程领域最受关注的应用之一。
4.2.1 自动补全(Code Autocompletion)
- 实时代码续写(如 VSCode Copilot)
- 单行、多行预测代码
4.2.2 代码解释与优化(Code Explanation & Refactoring)
- 自动解释函数意图
- 优化已有代码,重构结构
4.2.3 单元测试生成(Test Case Generation)
- 根据函数定义,自动生成对应的测试用例
本质:理解代码语义 + 基于模式生成补充内容。
4.3 图像生成(Image Generation)
在 Vision 领域,生成式 AI 也大放异彩。
4.3.1 文本生成图像(Text-to-Image)
- 代表模型:Midjourney、Stable Diffusion、DALL·E、豆包
- 应用场景:插画、广告设计、概念草图
4.3.2 图像编辑与增强(Image Editing)
- 局部修改(如 Inpainting)
- 风格迁移(Style Transfer)
- 超分辨率(Super-Resolution)
4.3.3 视频生成(Video Generation)
- 从文本描述生成短视频(如 Runway Gen-2、即梦)
- 视频风格化、自动剪辑
4.4 Agent(代理人)的出现
定义:具备自主行为与感知的 AI 应用
- AI 助理
- 工作流自动化
- AutoGPT
- ChatDev
四、如何提升模型输出质量?
虽然大型模型本身具备强大的生成能力,但要在实际应用中获得高质量输出,仍需要巧妙的方法与工程技巧。
本章将从 Prompt 优化、生成增强、模型适配、小模型趋势四个角度,系统讲解提升输出质量的核心手段。
5.1 Prompt 优化:引导模型更聪明地思考
Prompt(提示词)是引导模型生成的「指令」。在不改动模型本身的情况下,通过优化 Prompt,可以显著提升输出的相关性、准确性和创造性。
因为 Prompt 工程涉及的技巧非常丰富,包括角色设定、任务分解、思维链引导、格式控制等多种方法,我将这些内容整理到了一篇专门的文章中。如果你想深入学习如何编写高效的提示词,请查看我的 Prompt 工程指南,那里有详细的示例和最佳实践。
5.2 增强生成:AUG / RAG
单纯依靠模型已有知识可能不够。尤其当面对最新事实、专业领域知识时,引入外部知识源变得至关重要。
5.2.1 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合 「检索」 与 「生成」 的方法。
基本流程:
- 先根据用户输入,在外部知识库中检索相关内容(如文档、网页、数据库记录)。
- 将检索到的内容连同用户问题一起发送给生成模型。
- 模型基于检索结果,生成更准确、有依据的回答。
5.2.2 关键技术组成
- 向量数据库(Vector Database):将文本转成向量,支持高效的语义检索。
- 语义搜索(Semantic Search):不仅按关键词匹配,而是按意思找最相关的信息。
- 融合生成(Fusion Generation):在回答时综合已有知识和外部检索内容。
类比理解:RAG 就像是一个考生在答题时,不仅靠记忆,还能实时翻阅资料。
5.2.3 适用场景
| 场景类型 | 示例 | 为何适合用 RAG? |
|---|---|---|
| ✅ 知识问答 / 企业知识库问答 | “请问我们公司的年假政策是什么?” | 问题涉及专有知识,模型原生不掌握,需实时检索文档。 |
| ✅ 技术支持 / 产品手册查询 | “请告诉我 Model X 的维护步骤。” | 涉及大量产品文档,模型需检索指定资料。 |
| ✅ 法律、医学等高精度信息生成 | “根据 XX 条款,起草一份免责说明。” | 要求内容准确,不能 hallucinate,需引用法律条文。 |
| ✅ 论文写作 / 学术辅助 | “帮我总结一下这篇论文核心观点。” | 模型要从真实论文中抓信息,不是泛泛而谈。 |
| ✅ 对话型搜索 / 聊天机器人增强记忆 | “上次我说的目标 OKR 你还记得吗?” | 模型通过向量索引查找历史对话,比单靠上下文更稳。 |
| ✅ 财务、运营、商业分析报告生成 | “根据以下财报,总结业务亮点。” | 依赖结构化数据或报告原文,检索是关键。 |
// TODO:
因为涉及的技巧很多,所以单独写了一篇RAG。
5.3 模型微调与适配
有些场景,单靠 Prompt 和 RAG 还不足够,需要对模型本身进行适配。
5.3.1 Fine-tuning vs Prompt-tuning
- Fine-tuning(微调):在原模型基础上,继续用新数据训练若干步,适配特定任务。效果好,但计算资源消耗大。
- Prompt-tuning(提示词调优):冻结模型参数,仅训练一个小型的可学习 Prompt 向量(软提示)。成本低,灵活度高。
5.3.2 轻量化调优方法
针对大模型难以直接微调的问题,研究者提出了一系列轻量化方案:
- LoRA(Low-Rank Adaptation):只调整模型中的一小部分矩阵,显著降低微调成本。
- PEFT(Parameter-Efficient Fine-Tuning):广义指一切以更少参数适配的微调方法。
类比理解:Fine-tuning 是「大修发动机」,而 Prompt-tuning 和 LoRA 更像「加装外挂设备」。
5.4 小模型(SLM)趋势
近年来,除了继续扩展大模型(LLM),也有一股重要潮流:打造任务专用的小模型(SLM, Small Language Model)。
5.4.1 为什么需要小模型?
- 部署灵活:可以在本地服务器、边缘设备甚至手机上运行。
- 响应速度快:推理延迟低,体验流畅。
- 成本更低:计算资源消耗显著减少。
- 数据安全性高:本地推理,避免数据出云。
5.4.2 小模型的应用场景
- 企业内部知识问答系统
- 个人隐私助理
- 嵌入式智能设备
- IoT 物联网终端
类比理解:LLM 是航空母舰,SLM 是灵活机动的小型快艇,各有用武之地。
五、小结
提升 Generative AI 输出质量,不是单靠堆砌模型规模,而是需要综合运用:
- Prompt 工程
- 检索增强
- 轻量化微调
- 小模型创新
掌握这些方法,才能真正把 AI 变成高效、可靠的生产力工具。

