在大模型逐渐普及的今天,Retrieval-Augmented Generation(RAG)作为提升模型可靠性和知识覆盖的重要技术方案,越来越多地被用于企业问答、文档助手、客户支持等场景。本文将带你从 0 开始,基于 LangChain 框架,逐步实现一个可落地的 RAG 系统。
项目架构与技术选型
1.1 什么是 RAG?
RAG(Retrieval-Augmented Generation)是一种结合文档检索与大模型生成的技术架构,用于构建可控性强、知识更新灵活的问答系统。
传统的 LLM 只能回答训练数据中的知识,而 RAG 允许我们将外部文档作为上下文动态注入大模型,从而实现“开箱即问”的能力。
基本流程如下: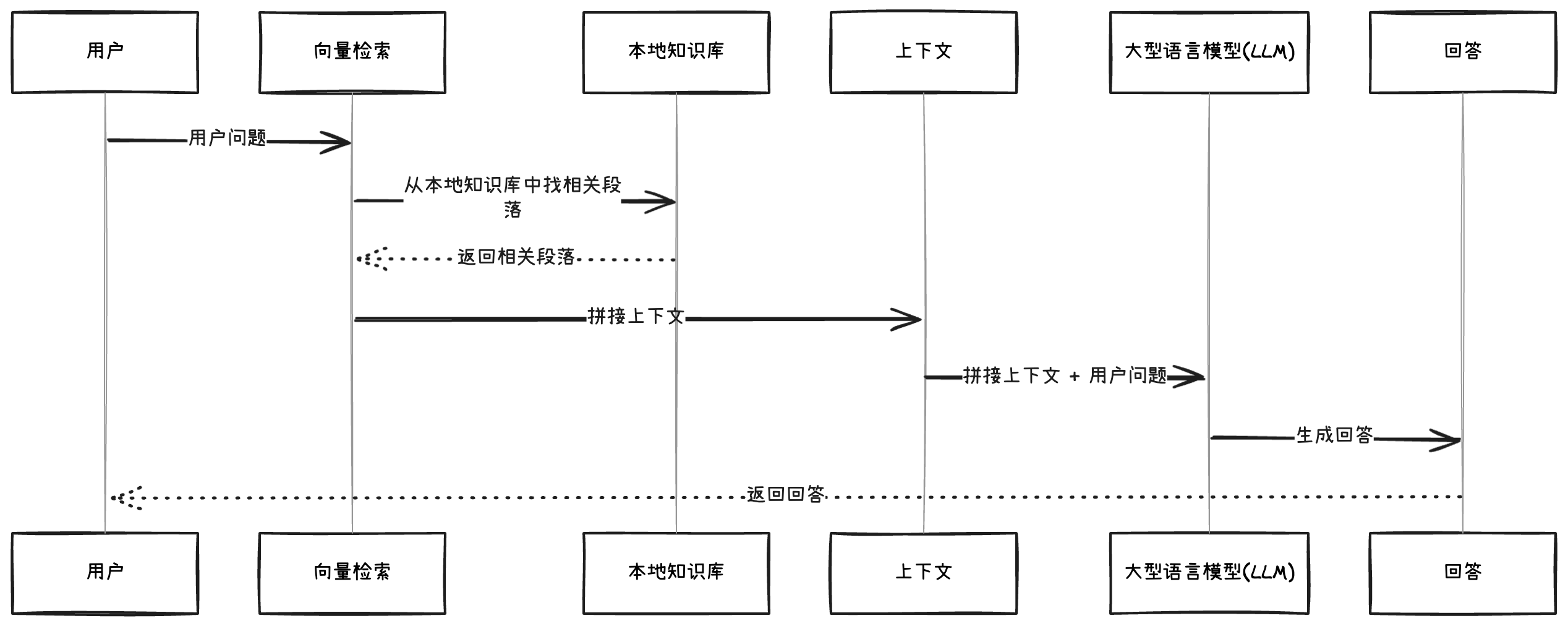
1.2 技术选型说明
| 技术 | 用途 |
|---|---|
| LangChain | 管理文档加载、文本分块、嵌入生成等流程 |
| OpenAI Embeddings | 将文本向量化为高维语义向量 |
| MemoryVectorStore | LangChain 提供的轻量级内存向量数据库,适合原型,小规模任务和本地开发 |
| OpenAI GPT (gpt-3.5 / gpt-4) | 语言生成模型,用于回答问题 |
使用 JavaScript 实现 RAG 系统
为什么选择 JavaScript 实现 RAG?
在 LangChain 最初的开发中,Python 是主流语言,很多功能模块(如 Embeddings、Retrieval、Chains)首先在 Python 端推出。但随着 LangChain.js 的发展,现在我们可以完全用 JavaScript/TypeScript 构建一个完整的 RAG 应用,并具备以下优势:
| 理由 | 描述 |
|---|---|
| 前端/全栈友好 | 如果你是前端或全栈开发者,JS/TS 是你熟悉的技术栈,无需切换语言 |
| 服务端一体化 | 可以直接将 LLM 接入集成到 Node.js 服务(如 Express)中,部署方便 |
| 生态兼容性强 | 能方便集成现有的 JS 库,如文件上传、数据库、前端组件库 |
| 支持 Edge Function | 可部署到 Vercel/Cloudflare 等平台,实现无服务器的轻量推理服务 |
2.3 本章目标
我们将在本章完成以下内容:
- 文档加载与分块(Text Split)
- 向量生成(OpenAIEmbeddings)
- 存储至 MemoryVectorStore
- 编写简洁的检索函数供后续生成使用
你需要准备:
Node.js 环境(建议版本 ≥ 18)
OpenAI API Key(保存在 .env 文件中)
示例文档:比如[google服务文档](https://policies.google.com/terms?hl=zh-CN)
2.4 完整流程图
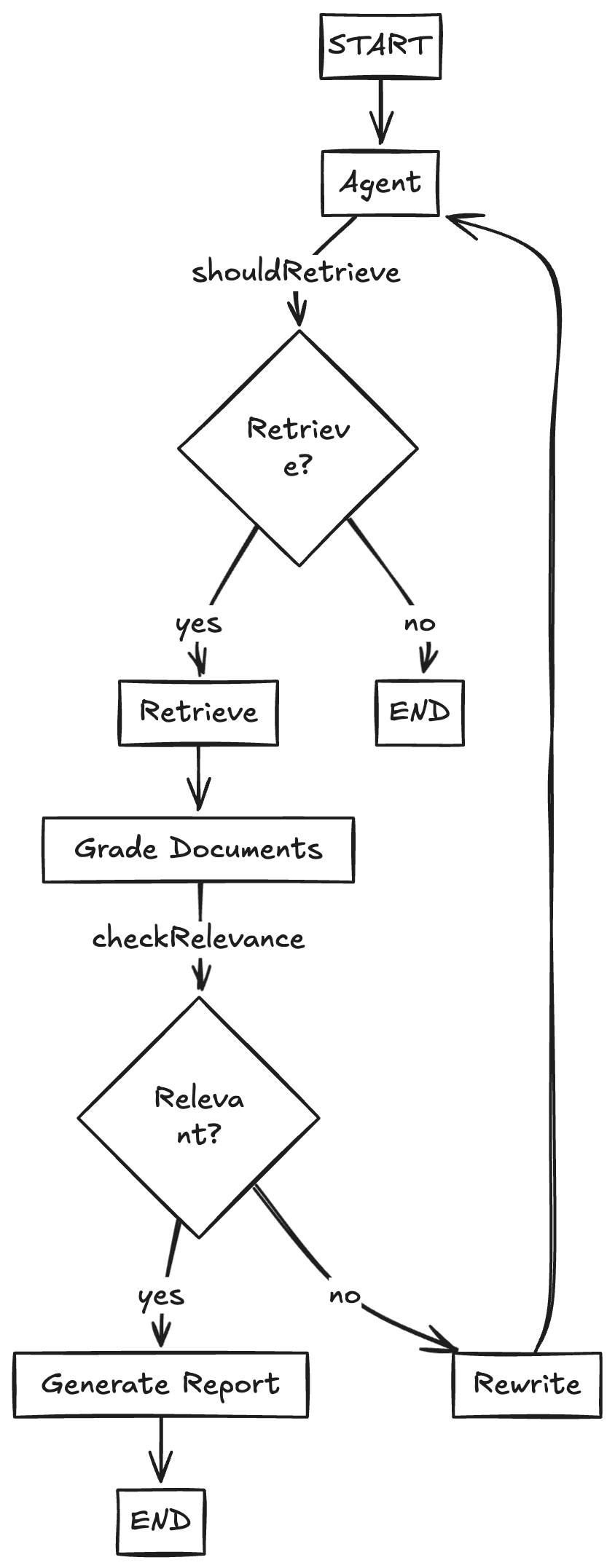
具体实现
1. 搭建一个LangGraph Server
通过脚手架可以直接创建一个LangGraph app,减少之间繁琐步骤
1. Install the LangGraph CLI
1 | $ npx @langchain/langgraph-cli@latest |
2. Create a LangGraph App
1 | $ npm create langgraph |
3.Install Dependencies
1 | cd your-repo |
4. Create a .env file
1 | LANGSMITH_API_KEY=lsv2... |
如何申请LANG SMITH API KEY
- jump to https://smith.langchain.com/
- 点击右上侧的developer button
- 点击左边的API KEY则就可以申请了
如何得到OPENAI API KEY
访问 zzz-api,之前有提供免费的API_KEY,现在好像没有了,本文只是提供一个link链接关于,如果申请OPENAI API KEY在国内,不能保证如果你充钱之后的后续服务。望谨慎充钱。(Deepseek不支持generating embeddings,所以本次案例不能采用deepseek来做展示)
2. 具体实现
1. 创建一个state 
在使用 LangGraph 构建基于节点的数据流图时,State(状态) 是核心概念之一。它定义了图中所有节点和边之间通信使用的共享上下文信息。理解并正确使用 State 是设计可靠 LangGraph 流程的关键。
什么是 State?
State 就是图的共享上下文,是每个 Node(节点)读写数据的“中心”。
每一个节点都会:
- 读取当前的 State
- 返回对 State 的局部更新
这些更新会通过 State 中定义的 Reducer 函数 应用到现有状态上。
如何定义 State?
通过 Annotation.Root() 定义一个 Annotation 对象,用于声明 State 的 schema(结构)。
1 | import { Annotation } from "@langchain/langgraph"; |
Reducer:状态更新规则
- 每个 key 可以附加一个 reducer 函数,控制如何处理节点返回的更新。
- 如果不定义,默认是直接 覆盖(override) 原值。
- 你可以自定义 reducer,比如对数组进行追加:
1 | const StateAnnotation = Annotation.Root({ |
多 Schema 管理(Input / Output / Internal)
LangGraph 支持为图定义多个 schema:
类型 用途
| 类型 | 用途 |
|---|---|
InputAnnotation |
输入 schema |
OutputAnnotation |
输出 schema |
OverallAnnotation |
运行时的完整内部状态 |
这种分离可以让你:
- 在输入中只传入一部分状态(如 user_input)
- 在输出中只提取部分结果(如 graph_output)
- 在中间节点中处理完整状态
🔹Graph 中的 State 是如何工作的?
- 每个节点读取一份当前 State 的 快照。
- 节点返回一个“局部更新对象”。
- Graph 自动将这些更新合并回 State:
如果 key 有 reducer,使用 reducer 处理
否则使用默认覆盖方式
🔹 消息(Messages)作为 State
在对话类系统中,一个常见模式是将历史消息作为 State 的一部分。
LangGraph 提供了内置的 messagesStateReducer 和 MessagesAnnotation 来支持这种模式:
1 | import { MessagesAnnotation } from "@langchain/langgraph"; |
相当于:
1 | import { Annotation, messagesStateReducer } from "@langchain/langgraph"; |
在本次的教程中,使用了定制化的reducer:
1 | export const GraphState = Annotation.Root({ |
2.构建基于 MemoryVectorStore 的检索工具节点(ToolNode)
在本节中,我们使用 JavaScript + LangChain 构建一个完整的文档检索组件。整个流程包括:
- 加载网页文档
- 文本分块(chunking)
- 构建向量数据库
- 构建 retriever 工具
- 集成为 ToolNode 节点
第一步:加载网页内容为文档
1 | const urls = ["https://policies.google.com/terms?hl=zh-CN"]; |
我们使用 CheerioWebBaseLoader 将网页内容抓取下来并转为 LangChain 文档对象。Promise.all 支持并发加载多个 URL,.flat() 将嵌套数组合并成单一文档列表。
第二步:对文档进行文本切块
1 | const textSplitter = new RecursiveCharacterTextSplitter({ |
长文本不适合直接用于嵌入,因此我们使用 RecursiveCharacterTextSplitter 将内容按 500 字符一块进行分割,并设置 50 字符重叠,保证语义连贯。
第三步:构建向量数据库(MemoryVectorStore)
1 | const vectorStore = await MemoryVectorStore.fromDocuments( |
我们使用 OpenAIEmbeddings 将文本块转为向量,并存入内存型向量数据库 MemoryVectorStore 中。此方式适合开发调试或轻量化场景,不依赖外部服务如 FAISS。
第四步:构建 Retriever 工具
1 | const retriever = vectorStore.asRetriever(); |
通过 createRetrieverTool 包装 Retriever,我们定义了一个结构化的工具,可供 Agent 调用。工具名称与描述信息将用于后续 LLM 选择工具时的参考依据。
第五步:构建 ToolNode 节点
1 | export const tools = [tool]; |
最终我们将工具包装为一个 ToolNode 节点,用于插入到 LangGraph 中执行调用流程。该节点将在运行时被 LLM 激活,并返回与问题相关的文档片段。
3. 构建 RAG 推理流程中的 LangGraph 节点函数
这一段代码是构建基于 LangGraph 的 Retrieval-Augmented Generation(RAG)流程的核心逻辑模块。它定义了多个节点函数,处理从用户提问、问题改写、文档检索、文档打分、判断是否继续检索,到最终生成答案的整个闭环流程。
shouldRetrieve:判断是否触发工具调用
1 | function shouldRetrieve(state: typeof GraphState.State): string { |
这是一个决策节点:如果上一条消息包含工具调用(如调用了 retriever 工具),流程继续(返回 “retrieve”);否则返回 END,流程终止。
gradeDocuments:判断检索结果是否相关
1 | async function gradeDocuments(state: typeof GraphState.State) { |
该函数用于打分检索结果是否与用户问题相关。它将检索到的文档传入 ChatPromptTemplate,通过一个预定义工具(give_relevance_score)返回 yes/no。
checkRelevance:根据评分判断是否继续
1 | function checkRelevance(state: typeof GraphState.State): string { |
这个节点判断打分结果,如果 binaryScore 是 yes,说明文档相关,可以继续;否则重新改写问题再尝试检索。
agent:调用带工具的 LLM 执行决策
1 | async function agent(state: typeof GraphState.State) { |
这是 LLM 决策节点,调用带有工具调用能力的 LLM,根据上下文决定是否触发 retriever 工具。此处会过滤掉评分工具调用信息,避免影响模型判断
rewrite:改写不清晰的问题
1 | async function rewrite(state: typeof GraphState.State) { |
该节点用于处理不相关或语义模糊的用户提问。它使用 LLM 对原问题进行语义增强和重写,从而提高检索效果。
generate:基于文档生成最终答案
1 | async function generate(state: typeof GraphState.State) { |
这是最后一步:基于之前的检索结果生成最终答案。它拉取了一个 RAG Prompt 模板(rlm/rag-prompt),填入上下文文档和用户问题,并返回 LLM 的响应。
构建 LangGraph 工作流主图:RAG 推理流程图
这段代码基于 @langchain/langgraph 构建了一个带条件分支的推理流程图。整个图负责 orchestrate 多步操作,从提问到文档检索、改写、判断、最终生成回答。
依赖导入
1 | import { END, StateGraph, START } from "@langchain/langgraph"; |
- StateGraph:核心图结构构造器。
- START / END:特殊标识起点和终点。
- GraphState:定义状态结构(上下文信息如 messages)。
- edges:RAG 流程中每个节点的处理逻辑。
- toolNode:实际执行文档检索的节点(如调用向量数据库)。
创建图结构并添加节点
1 | const workflow = new StateGraph(GraphState) |
在 StateGraph 中注册流程节点:
- agent:调用带工具能力的 LLM。
- retrieve:执行检索操作。
- gradeDocuments:给检索文档评分。
- rewrite:改写不相关的问题。
- generate:最终回答生成。
定义执行路径:从 START 到 agent
1 | workflow.addEdge(START, "agent"); |
流程从起点开始,首先调用 agent 节点生成思考结果。
判断是否需要检索
1 | workflow.addConditionalEdges("agent", shouldRetrieve); |
shouldRetrieve 是一个决策函数:
- 返回 “retrieve”:进入 retrieve 检索节点。
- 返回 END:直接结束。
📊 检索后打分
1 | workflow.addEdge("retrieve", "gradeDocuments"); |
文档检索后,会执行 gradeDocuments,评估其与问题的相关性。
判断文档是否足够好
1 | workflow.addConditionalEdges( |
如果 checkRelevance 返回 yes:文档质量高,进入 generate。
否则进入 rewrite 节点,重新改写问题再回到 agent。
终点和回环逻辑
1 | workflow.addEdge("generate", END); |
generate 后结束整个流程。
改写后的问题再次进入 agent,形成循环,直到找到相关答案。
编译工作流
1 | export const graph = workflow.compile(); |
最终导出编译好的 graph,可直接通过 .invoke() 调用执行。这个图可以被用作 LangGraph 多轮推理系统的主逻辑控制器。
以上就是全部code实现,想要访问阅览完整代码,请点击这里。

